 |
 |
 |
 |
 |
|
facial animation
Tintown was largely created from a series of
scripts used to composite, crop, and generate video sequences
from files rendered in SoftImage.
For Example:
Rather than labor over a detailed specification of key frames for the
lip-synching sequences. I created an application that would:
- 1) Parse relevant features (phonemes, intensities) from sound files.
- 2) Map those features into a data file or time series format.
- 3) Read the time series of events, interpreting and/or choosing
from a set of pre-rendered images.
|
|
|
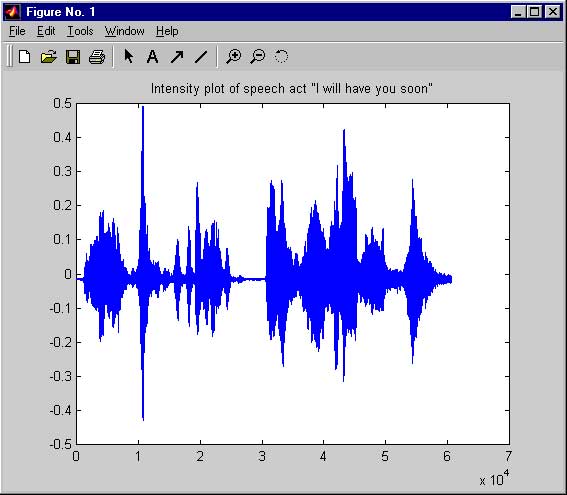
The features that I extrapolated depended largely on the sequence
at hand. For loosely defined scenes, simply doing an intensity estimation
and change of thresholds would satisfy for a series of key frames.
For tight lip-synch animation, one would need to do in-depth
pattern/voice recognition to extract the key moments from the source file.
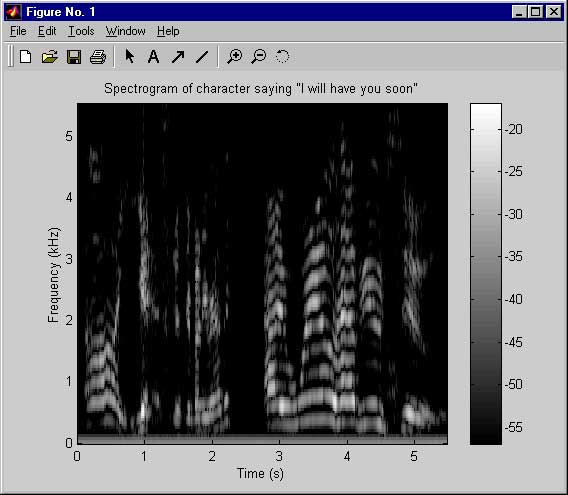
Figure no. 1 shows a monochrome spectrogram with a dB scale.
|
|
|
The beauty of this process lies in the fact that the recognizer only has to match phonemes from the signal. I do not need to
worry that the recognizer identify words, or word units. Typically a mel-cepstrum front end for any industrial recognizer or a
gaussian mixture distribution to a collection of observation vectors are all that are needed to achieve relatively good lip synching
matches. The following five images are examples of pre rendered phones which one might use for a production run.
|
 |
 |
 |
 |
 |
|
Now in some aspects, determined by the level or resolution that you
break this task down, this process can be viewed as a behavioral
approach to rendering lip-synching events.
Each speech act or event is interpreted, or decomposed, into the
repetition, or statistical nature of the phonemes reoccurrence.
One would simply have to iterate over the data set, the phonemes
then become leaf nodes in a recursive tree of decisions. From this perspective
speech acts are repeatable, and definable behaviors that show marked tendencies
to display emergent behavior, similar to the types of phenomenon so often being modelled
in the literature i.e. ants, birds, cows, fish, etc.
|
|
So in summary,
- One could simply just generate a randomly selected sequence of
phonemes, or frames at major shifts of intensity levels, hills and valleys, max and min, whatever your flavor, etc.
- OR one could alternatively have chosen to select very refined and specific instances
of the sound wave as they map out to the actual sounds that we knoware made during speech.
What then becomes the central compelling issue is how one might go about introducing personality and character, or mood
into the articulation of these events. This is where one might identify that the hand of the experienced character animator
could easily be differentiated from the mechanical and scripted acts of the machine, such as is found in synthesized speech.
This is a compelling question, one that deserves a closer examination.
More on that later ...
****
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
